What reused prompt tokens mean
They indicate that OpenAI reported previously reusable prompt content on the provider side. This is not the same as a full local cache hit where the request never needs to go upstream again.
Reused prompt tokens are only meaningful when they come from real provider-reported behavior. AI Optimizer keeps that signal visible without blurring it together with exact local cache hits.
The honest way to see reused prompt tokens in OpenAI is to surface them only when OpenAI reports real reuse. That signal should stay separate from exact local cache hits, because those are different kinds of wins.
They indicate that OpenAI reported previously reusable prompt content on the provider side. This is not the same as a full local cache hit where the request never needs to go upstream again.
Many dashboards blur local caching and provider reuse together. That makes the numbers look better, but it also makes them less useful for decision-making.
Exact cache hits and reused prompt tokens tell you different things about your workflow.
Fully served from the local cache. Strongest direct proof of repeat-workflow savings.
Only counted when OpenAI reports real reused prompt tokens.
Provider-reported reuse that helps explain partial savings without pretending they are full cache hits.
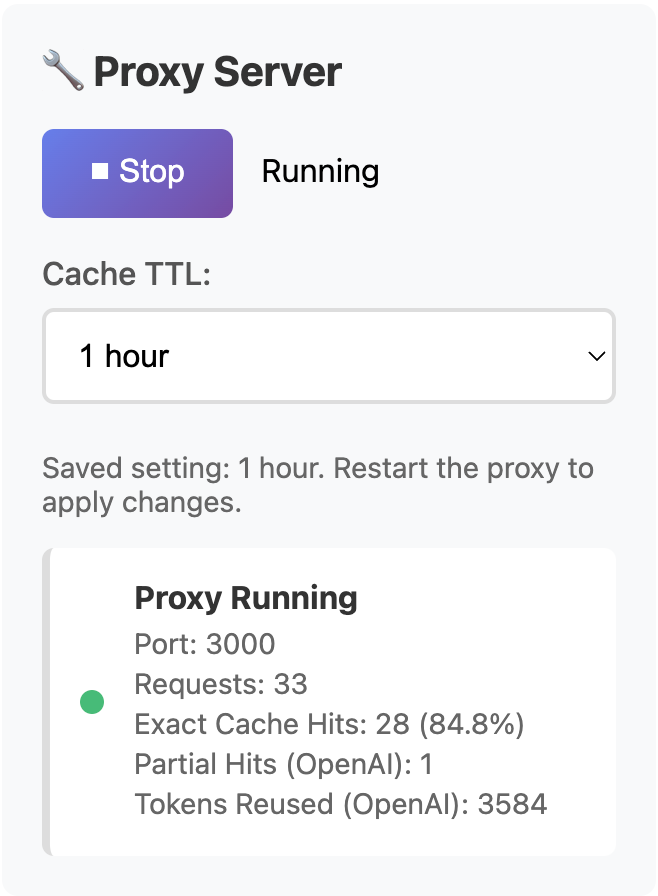
If OpenAI does not report reused prompt tokens, AI Optimizer does not invent them. That keeps the proof believable and makes it easier to understand what is actually happening in production.
This is especially useful for teams comparing workflows, evaluating provider behavior, or trying to explain savings without inflated marketing claims.
No. That depends on provider-side behavior and what OpenAI actually reports back.
No. A cache hit is local. Reused prompt tokens are provider-reported reuse.
Because combining them hides what is truly local optimization versus what the provider reported upstream.
Use AI Optimizer to keep exact local hits and provider-reported OpenAI reuse visible, separate, and easier to trust.