Exact cache hits
This is the clearest signal. The repeated request was served locally through AI Optimizer instead of paying for the same upstream call again. That is the strongest direct proof of repeated-request savings inside your own workflow.
Not all caching signals mean the same thing. AI Optimizer separates exact local cache hits from provider-side reuse so you can see what actually happened and judge savings more honestly.
An exact cache hit means the repeated request was fully served from AI Optimizer’s local cache. A partial hit means some reuse happened at the provider layer, but not a full local exact-hit outcome. OpenAI, Anthropic, and Gemini can all report useful caching signals, but those signals follow provider rules like token minimums, prefix or context matching, and retention limits. Treating all of that as the same thing makes optimization harder to trust.
This is the clearest signal. The repeated request was served locally through AI Optimizer instead of paying for the same upstream call again. That is the strongest direct proof of repeated-request savings inside your own workflow.
This is a narrower signal. Some provider-side reuse may have happened, but it was not the same as a full local cache resolution. Useful signal, yes. Same thing as a local exact hit, no.
Reporting only helps if it supports better decisions.
You want to know whether AI Optimizer’s local cache actually handled the repeated request or whether the provider reported a smaller reuse signal upstream. Those are different layers with different rules.
You want believable savings language, not one blended metric that makes every kind of reuse sound equally strong. Exact local hits, provider-side reuse, and reused tokens should not all be described like the same thing.
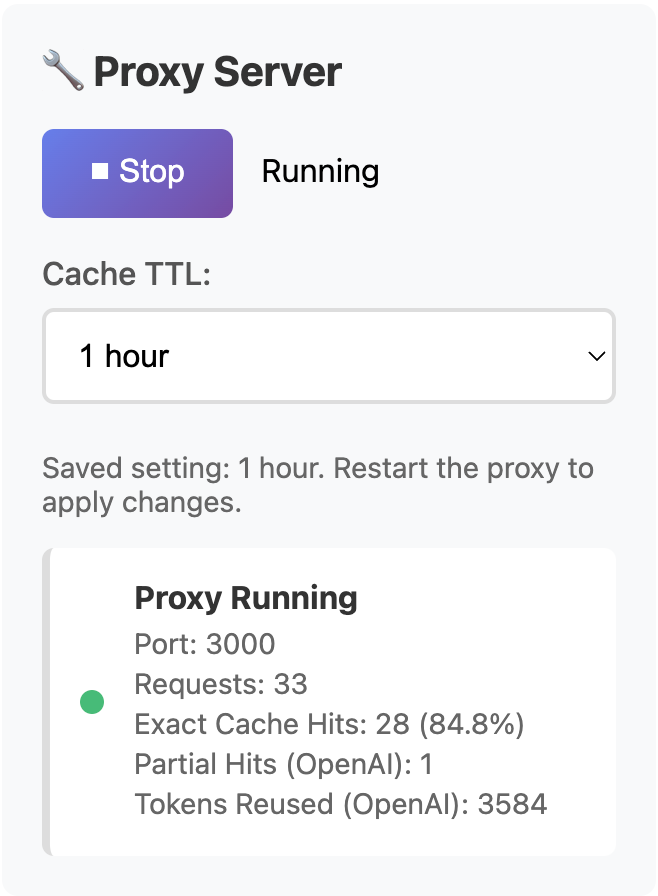
Exact cache hits are the strongest direct signal for repeated local savings because the repeated request was fully handled inside your own workflow.
Partial hits need context. OpenAI, Anthropic, and Gemini all have caching behavior, but their caching usually depends on provider-side rules like token minimums, prefix or context matching, and retention windows.
Good tooling should not collapse local exact hits, provider-side reuse, and reused tokens into one feel-good number that hides what actually happened.
Yes. OpenAI, Anthropic, and Gemini caching can absolutely help in the right workflows. The point is not that provider caching is bad. The point is that provider caching is not the same thing as a local exact cache hit you can control directly.
Because merged metrics are easier to market but worse for operational truth. If you want to know what is really saving money in a repeated workflow, you need to keep exact local hits separate from softer upstream reuse signals.
AI Optimizer adds a local caching and control layer in front of your workflow. That means user-controlled TTL, visible local proof, and a cleaner fit for repeated scripts, cron jobs, prompt testing, CLI loops, and agent workflows.
Because provider caching usually depends on model support, token thresholds, retention limits, and exact prefix or context reuse. That means provider caching can help, but it still follows rules you do not fully control.
Yes. They solve different layers. Provider caching can help upstream. AI Optimizer helps at the local workflow layer by making repeated-request behavior more visible, more controllable, and easier to evaluate.
AI Optimizer keeps exact local hits separate from provider-side reuse so your team can understand repeated-request behavior more clearly and make better optimization decisions.