Local proxy path
Requests are sent through http://localhost:3000/v1 so AI Optimizer sits between the workflow and the upstream provider.
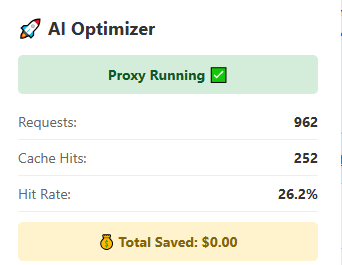
This page is where AI Optimizer earns trust. The goal is simple: show repeat request behavior clearly enough that a technical buyer can see the product is doing useful work, not just making a vague promise.
AI Optimizer can cache repeated OpenAI and Anthropic requests through a local proxy workflow. In repeat tests, identical requests increased cacheHits instead of sending the same work upstream at full cost again, which makes the product a strong fit for repeat-heavy scripts, automations, and agent workflows.
The proof case is intentionally boring: same request shape, same provider, same local proxy path, and repeated calls checked against request totals and cache-hit counts.
Requests are sent through http://localhost:3000/v1 so AI Optimizer sits between the workflow and the upstream provider.
Identical or near-identical requests are repeated to see whether the app increments cacheHits instead of paying full price for the same work again.
OpenAI is a natural fit for this style of proof because many scripts, tools, and repeat-heavy automations send the same request pattern over and over. The page should show a simple before-and-after stats example with the repeated call path kept stable.
Anthropic support matters because it proves the local proxy model is not only for one provider. The strongest example here is a repeated Claude request that still hit cache later inside the TTL window.
A cache hit means the repeated request was resolved locally instead of paying for the same full upstream work again. That is most valuable when workflows repeat on a schedule or through common tool loops.
Cache behavior only stays useful if repeated requests happen within the configured TTL window. That is why recurring jobs, cron prompts, and repeated scripts are such a clean fit for this workflow.
The value of a proof page is precision. It should show where AI Optimizer is strong without pretending every workflow will behave the same way.
Local proxy caching works. OpenAI and Anthropic both fit the model. Repeat-heavy workflows can reduce repeated API waste when prompts and request bodies stay stable enough to hit cache.
It does not mean every prompt will hit cache. Highly dynamic request bodies, changing timestamps, or constantly unique prompts reduce hit rate. The product works best where repetition is real.
Install AI Optimizer, route traffic through localhost, confirm cache-hit behavior, and then apply the same pattern to repeat-heavy tools, scripts, and automations.