Where repetition shows up
- scripts rerunning the same task
- agents revisiting the same request patterns
- cron jobs repeating on schedule
- local testing replaying identical calls
- reusable AI workflows creating stable request structure
AI Optimizer is a local caching proxy for OpenAI- and Anthropic-compatible workflows. When a script, agent, or scheduled job repeats an identical request inside your chosen TTL, the response is served from your machine instead of being sent upstream again.
Change one base URL. Set a TTL that fits the workflow. Then watch the hit counter in local stats and the browser popup so you can prove the savings instead of guessing.
A lot of AI usage is not one-off chatting. It is repeat-heavy operational work that quietly sends the same or nearly identical requests again and again.
Even when a workflow feels dynamic, many requests are exact repeats at the API level. When that happens, paying full price every time is waste.
If a scheduled job runs every 15 minutes, that is 96 runs per day and 2,880 runs per month. When those requests are identical, repeat cost adds up fast.
The proof uses a deterministic scheduled AI job that sends the same known request through AI Optimizer and expects the same known response: CACHE_TEST_OK.
This page is built around a deterministic scheduled AI job, a chosen TTL, visible cache-hit stats, and a browser popup that shows the running totals locally. As of July 3, 2026, 209 of 610 requests were served locally — a 34.3% hit rate.
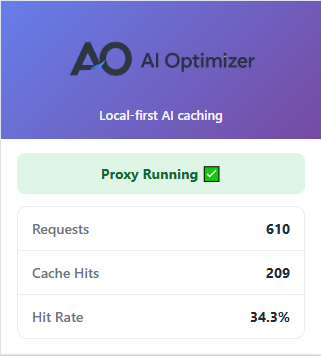
In the current proof run, 209 of 610 requests were served locally — a 34.3% hit rate, visible as it happens instead of guessed from a bill later.

A deterministic proof run is scheduled every 15 minutes, so the repeat behavior is automated and inspectable.
The cache window is chosen to fit the workflow instead of relying on provider defaults or vague behavior.
Fair question. They do — but that solves a different problem than exact repeated-request caching for repeat-heavy local workflows.
Provider-side caching doesn’t solve every repeat-heavy workflow. AI Optimizer is for the workflows where exact repeated local requests, chosen TTL windows, and visible proof still matter.
AI Optimizer is strongest where repeated AI work is already part of normal operations.
Rerun the same prompts and tasks without paying full price every time.
Reduce waste from repeated agent loops, retries, and recurring reasoning patterns.
Match TTL to scheduled jobs and turn repeat-heavy runs into measurable cache hits.
Cut repeat cost in recurring background workflows and operational pipelines.
Support repeat-heavy testing, prompt refinement, and local AI-assisted development.
Reduce waste in standardized AI tasks like review, scaffolding, tests, and setup.
AI Optimizer is not magic. It is strongest in a narrow, provable lane.
It works best when requests are truly repeated, when the workflow runs often enough to make those repeats meaningful, and when you want visible local proof instead of hoping the economics work out.
Simple operational flow. No theory exercise required.
Use AI Optimizer as the local endpoint for OpenAI- or Anthropic-compatible requests.
Scripts, agents, cron jobs, and automations keep working as usual.
When the same request appears again, AI Optimizer serves the cached result locally.
Pick one script or cron job you already run. One base URL change, one TTL, one visible cache hit.
Start with the 14-day free trial. If it proves useful in one real workflow, AI Optimizer is $4.99 USD/month after trial.
OPENAI_BASE_URL=http://localhost:3000/v1